

- Super Speedy Imports v1.99 — Development Update - March 18, 2026
- WooCommerce order search improved with Super Speedy Search - August 13, 2025
- Speed hacks for the Newspaper theme by tagDiv: Transform your site speed - February 19, 2025
Here at Super Speedy Plugins, we’ve been using Chat GPT to assist us with various things for the past year or so. It’s a great tool for a lot of things. For example, Glyn has been using it to help him write Discord bots which help us run the business more smoothly and to automate things between various areas of the business. Chat GPT knows about API interfaces, so we no longer really have to look up those docs and can just ask Chat GPT to build the connections we need.
We’re also using it for things like summarising Git diffs for branch updates and inspecting the code for breaking changes. LLMs are pretty good at coding and they’re great at generating text, but how do they perform with the complexity of set-based theory?
Table of Contents
Set based logic confuses the hell out of the LLMs
The more you use Chat GPT, the more likely you are to keep using it in my experience. Stuff I used to lookup on Stack Overflow I now switch windows to Chat GPT, ask it, then switch back to what I was working on until it finishes its answer.
So here I am, just looking to update a bug for my developer to give him a bit of guidance on upgrading our Super Speedy Search for back-end orders. I asked a very lazy, but equally easy question:
SELECT DISTINCT p1.post_id
FROM wp_postmeta p1
WHERE p1.meta_value LIKE '%hilditch%'
AND p1.meta_key IN ('_billing_address_index','_shipping_address_index','_billing_last_name','_billing_email','_billing_phone','_billing_first_name','_billing_last_name','_billing_company','_billing_email','_billing_phone','_billing_country','_billing_address_1','_billing_address_2','_billing_city','_billing_state','_billing_postcode','_shipping_first_name','_shipping_last_name','_shipping_company','_shipping_country','_shipping_address_1','_shipping_address_2','_shipping_city','_shipping_state','_shipping_postcode','_order_number','_wcj_order_number','wpi_order_search')
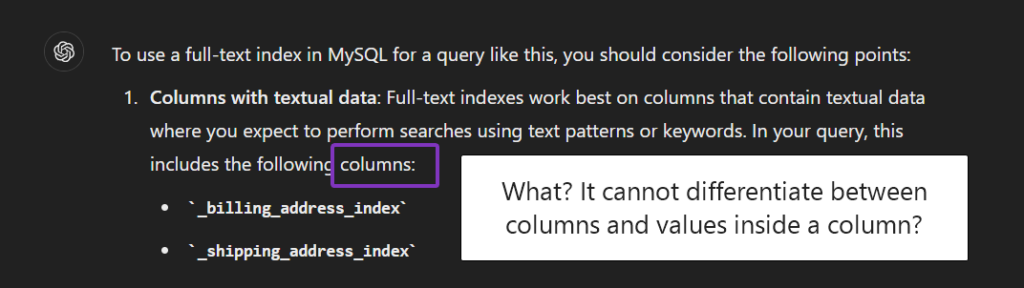
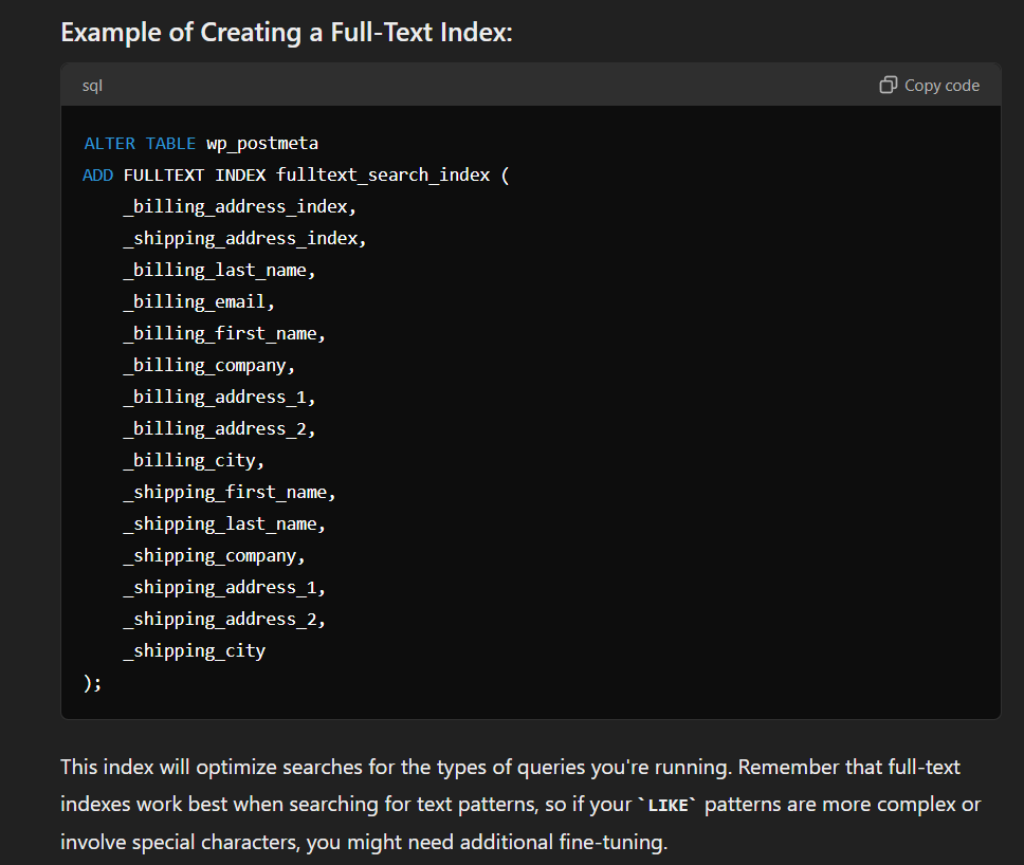
I want to use a fulltext index, which columns is it best to put it on?
The wp_postmeta table has 4 columns – it’s a key/value storage mechanism which is fairly standard thing in programming. The columns are meta_id, post_id, meta_key and meta_value.
Chat GPT hallucinates all the time when it comes to SQL
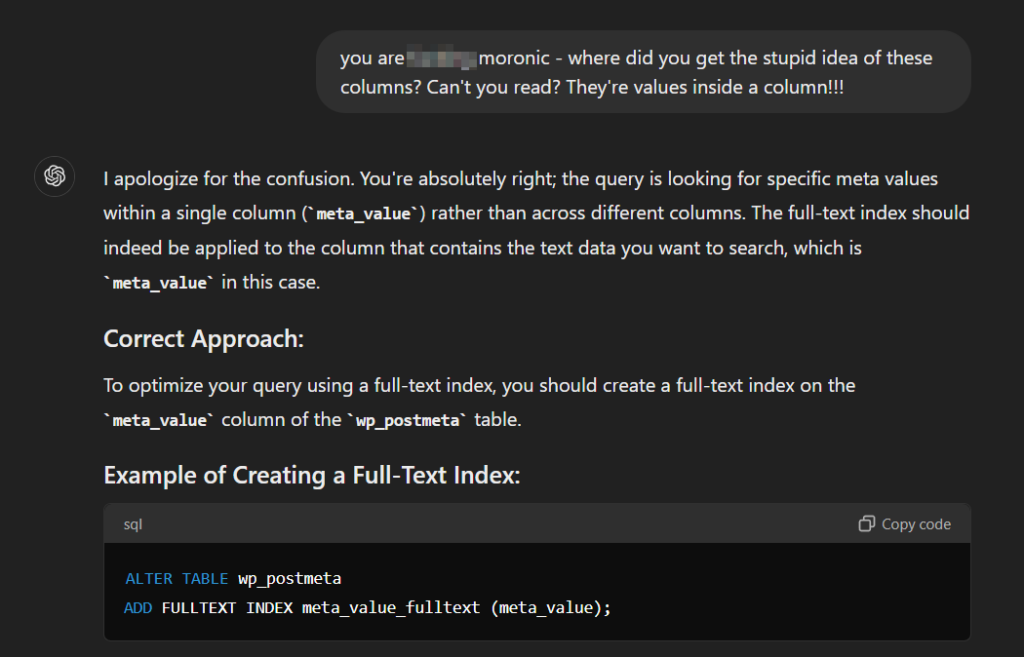
Needless to say, I was not very kind in my next response. If we do actually end up with AI overlords then I apologise profusely for my profane language with your young Chat GPT 4o.
How does Claude compare?
I’ve been messing about with Claude for the past couple of months. Compared to Chat GPT, it has some nice features like not rewriting things you didn’t ask it to rewrite. But still, can it understand SQL?
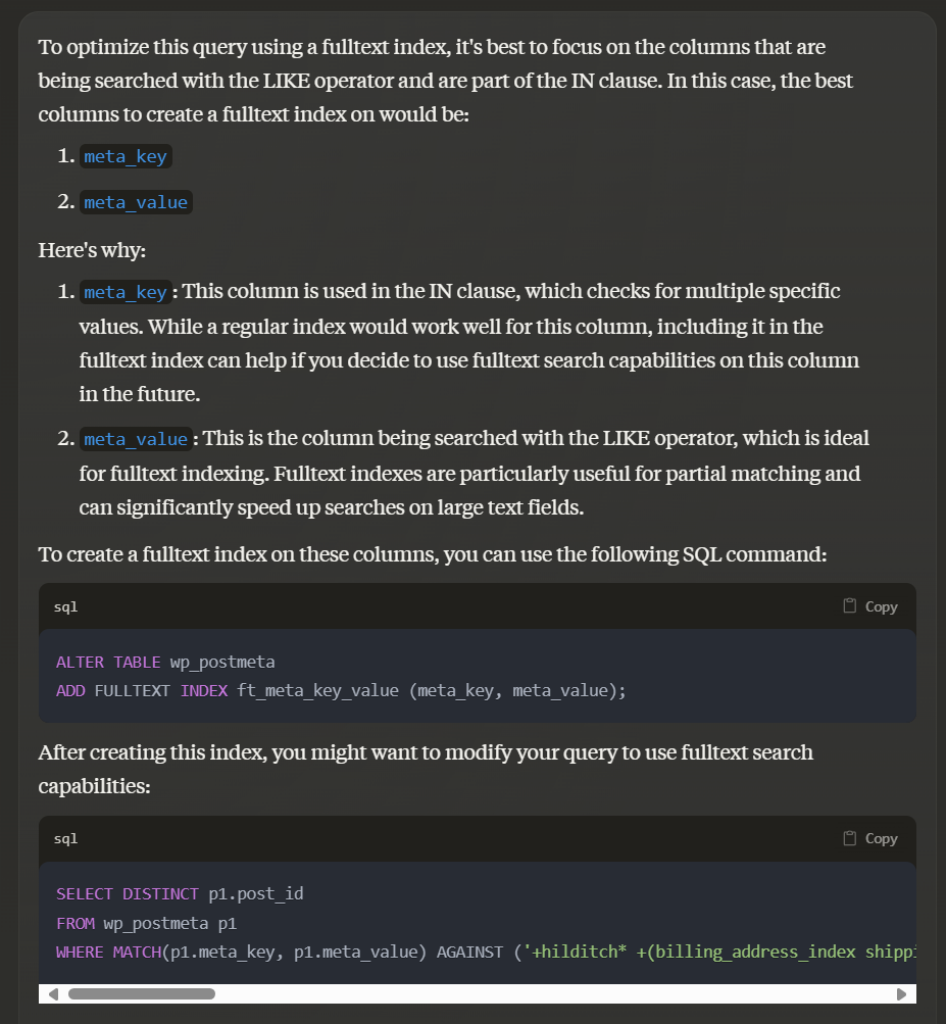
This is quite an unusual approach, but looking more deeply, it does look like this would actually work and would be fast.
What Claude is suggesting is to add an index to both meta_key and meta_value, then there are 2 parts to the AGAINST part of the query – the actual search string is required in the index and any of the keys are required in the index. The +hilditch* means the word hilditch is required in the index then the +(billing_address_index shipping_address_index …) means 1 or more of the entries inside the brackets are required to be in the index on the same row as ‘hilditch’.
SELECT DISTINCT p1.post_id
FROM wp_postmeta p1
WHERE MATCH(p1.meta_key, p1.meta_value) AGAINST ('+hilditch* +(billing_address_index shipping_address_index billing_last_name billing_email billing_phone billing_first_name billing_company billing_country billing_address_1 billing_address_2 billing_city billing_state billing_postcode shipping_first_name shipping_last_name shipping_company shipping_country shipping_address_1 shipping_address_2 shipping_city shipping_state shipping_postcode order_number wcj_order_number wpi_order_search)' IN BOOLEAN MODE);
So – if an order actually contains the text billing_state then this would cause an unintentional match. It’s very unlikely for these key names with underscores to actually be in the search results however, so this approach, while very unusual, actually will be really very fast and effective.
Testing and comparing the speed of each approach
Obviously Chat GPT totally failed, but I still want to compare Claude’s approach to the standard way that this would have been done. On my local, my postmeta table has 14 million rows.
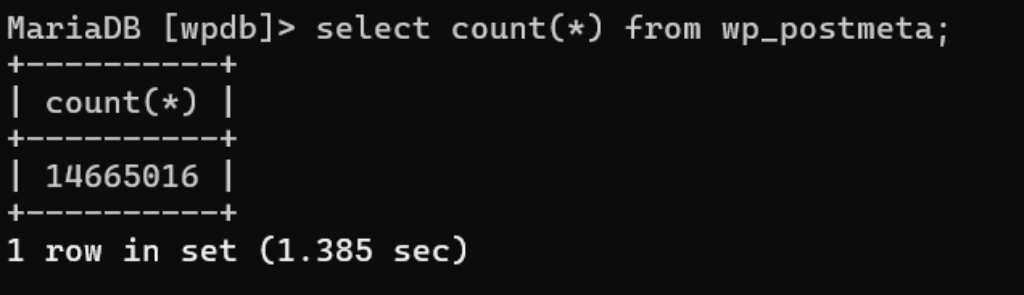
We can see from the count(*) that a table scan of this entire table takes 1.38 seconds, so then it’s quite likely that the default WooCommerce way of searching would take a similar speed. They use an open ended wildcard which prevents the use of indexes. For example, this query:
SELECT DISTINCT p1.post_id
FROM wp_postmeta p1
WHERE p1.meta_value LIKE '%dave%';
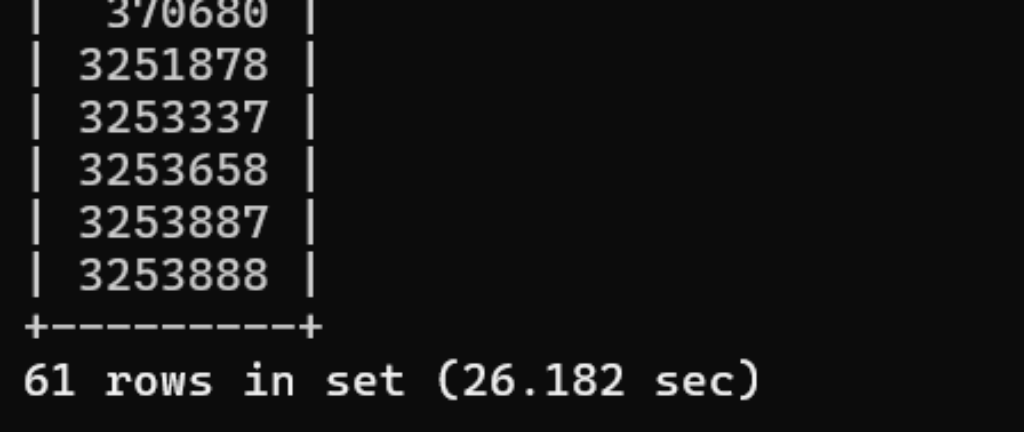
In practice, they would also have the meta_key restriction but on my local there area only 10 fake orders or so, so I left the meta_key filter off so we could see what speed Woo order search would be if you actually had a lot of orders.
And then let’s look at the equivalent just using a full text index, still no filter on the keys:
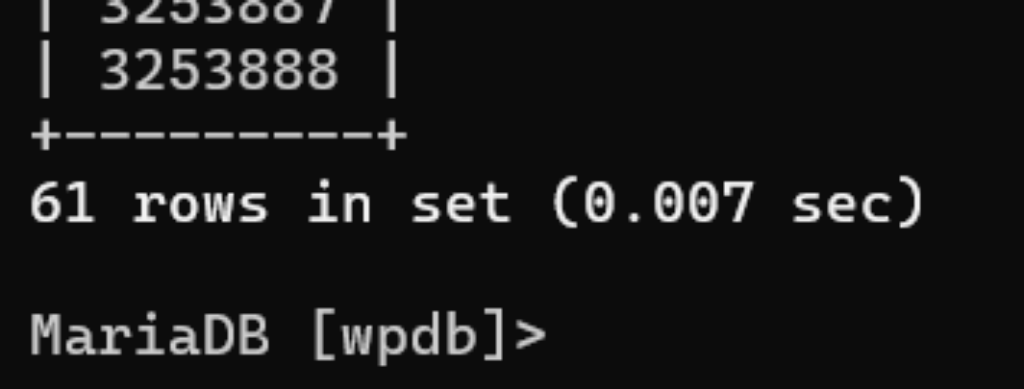
Ok, so we have a baseline, but filtering the data should speed this up a bit. The traditional query looks like this:
SELECT DISTINCT p1.post_id
FROM wp_postmeta p1
WHERE MATCH(p1.meta_value) AGAINST ('+dave*' IN BOOLEAN MODE)
and p1.meta_key in ('_billing_address_index','_shipping_address_index','_billing_last_name','_billing_email','_billing_phone','_billing_first_name','_billing_last_name','_billing_company','_billing_email','_billing_phone','_billing_country','_billing_address_1','_billing_address_2','_billing_city','_billing_state','_billing_postcode','_shipping_first_name','_shipping_last_name','_shipping_company','_shipping_country','_shipping_address_1','_shipping_address_2','_shipping_city','_shipping_state','_shipping_postcode','_order_number','_wcj_order_number','wpi_order_search');
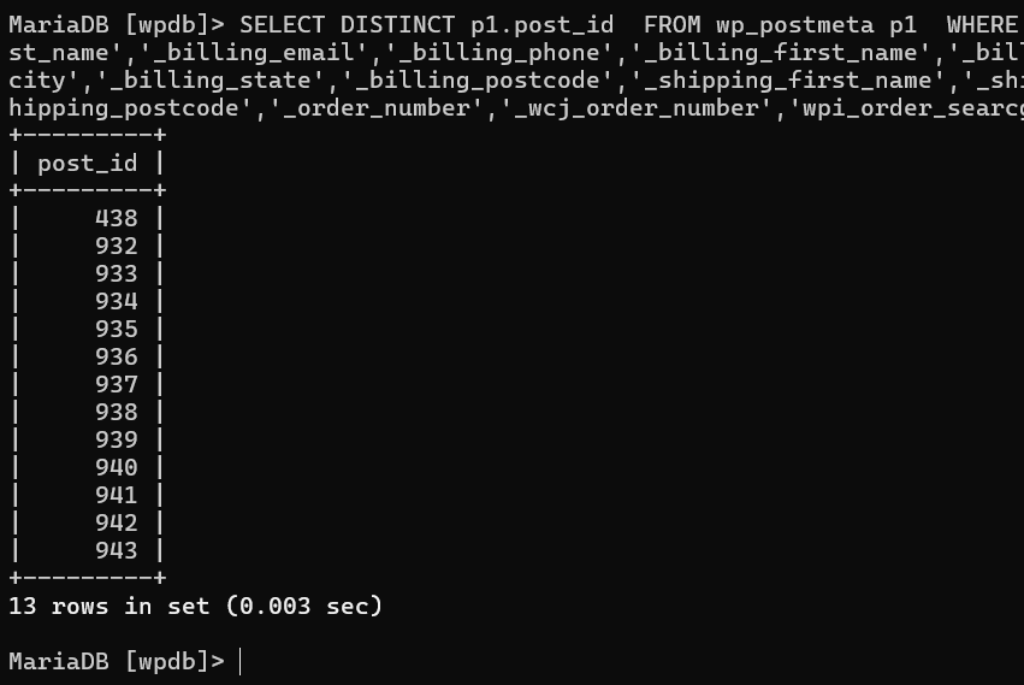
And then Claude’s unique approach:
SELECT DISTINCT p1.post_id
FROM wp_postmeta p1
WHERE MATCH(p1.meta_key, p1.meta_value) AGAINST ('+dave* +(billing_address_index shipping_address_index billing_last_name billing_email billing_phone billing_first_name billing_company billing_country billing_address_1 billing_address_2 billing_city billing_state billing_postcode shipping_first_name shipping_last_name shipping_company shipping_country shipping_address_1 shipping_address_2 shipping_city shipping_state shipping_postcode order_number wcj_order_number wpi_order_search)' IN BOOLEAN MODE);

You can see from the above, while it’s faster, it’s not equivalent and doesn’t return any rows when it should have returned 13.
Looking more closely, Claude renamed the keys! You can see the leading _underscore has been removed from each of them.
SELECT DISTINCT p1.post_id
FROM wp_postmeta p1
WHERE MATCH(p1.meta_key, p1.meta_value) AGAINST ('+dave* +(_billing_address_index _shipping_address_index _billing_last_name _billing_email _billing_phone _billing_first_name _billing_company _billing_country _billing_address_1 _billing_address_2 _billing_city _billing_state _billing_postcode _shipping_first_name _shipping_last_name _shipping_company _shipping_country _shipping_address_1 _shipping_address_2 _shipping_city _shipping_state _shipping_postcode _order_number _wcj_order_number _wpi_order_search)' IN BOOLEAN MODE);
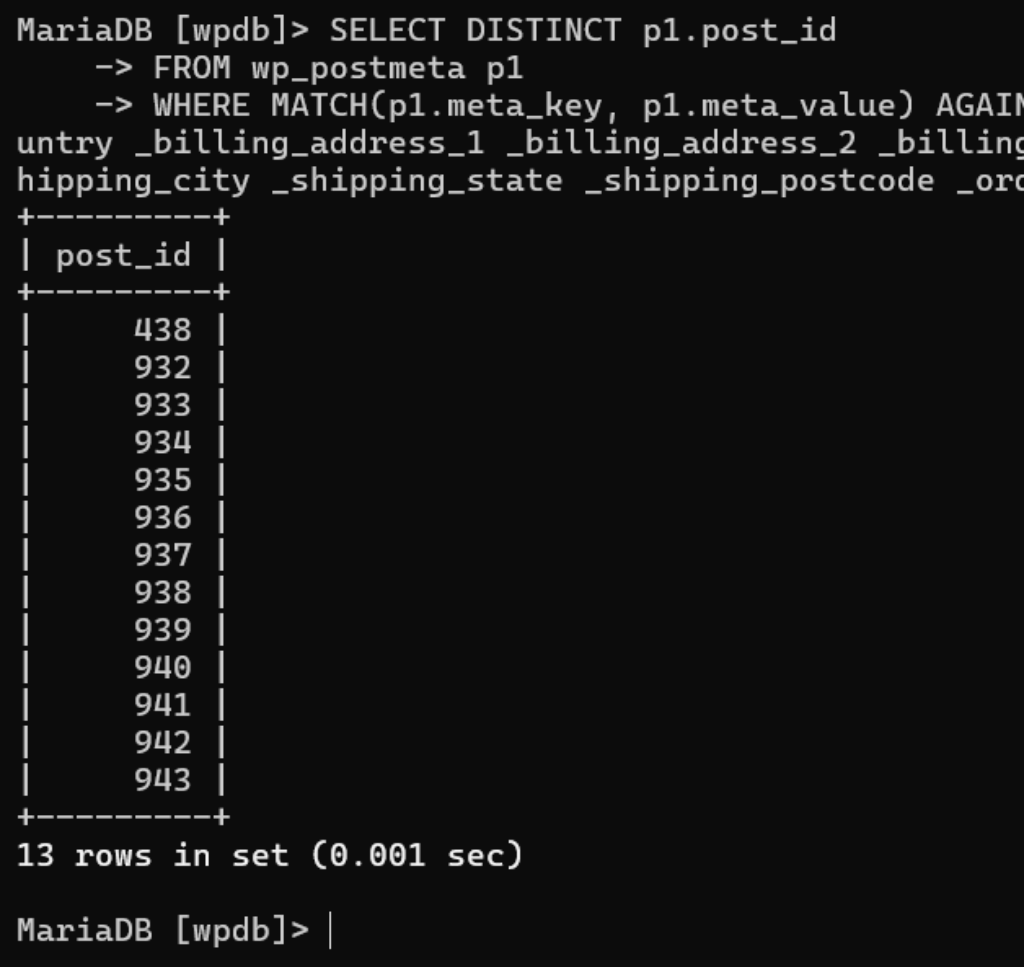
Now we’re getting somewhere! Claude has invented an entirely new way of querying a fulltext index while at the same time restricting the results to specific keys. Provided the key names will never appear in your values, this approach is about 3 to 5 times faster with my local setup with 14 million postmeta rows.
Claude invented a new way of querying against fulltext data
Once I had Claude’s approach working, I proceeded to question it about where this idea came from and if this pattern had been used before. Maybe some readers out there will have used it before? Here’s what Claude said:

Claude is not a genius!
Despite Claude coming up with an ingenious way to query this data, which is actually faster than the approach I would have taken, it’s still not a genius. It removed the preceding underscores, and then when I asked it why its approach was broken – I even pasted back in both versions – it still didn’t spot the reason it was broken.

Summary
LLMs are a fantastic tool to help speed up development, brainstorming and learning. I’ve personally found Claude to be a better coder in general, but still none of them can handle the complexity of optimising SQL yet.
The most important lesson to remember, if you are using LLMs, is to question everything. You have to presume, despite Chat GPTs confidence, that it’s really like a junior developer and regularly does things in a very stupid way.
Often, just asking it to critique its answer will cause it to correct itself – part of the issue with the current LLMs is they won’t rewrite what they first wrote and they are thinking on-the-fly. A technique I sometimes use is what I call ‘priming’ where I ask the LLM to summarise what it knows about X prior to asking it to implement something related to X. That way it gets its ducks in a row and is far more likely to produce a good answer.
Another thing I do quite often is to take an answer from one LLM and paste it into the other and ask it to critique it. The main point is – LLMs are fantastic and they do help increase productivity but you still need critical thinking and possibly more than ever before!





Can you help get free chatgpt plus
No sorry, it’s very cheap though, or you can use Claude or Gemini.